Organisation of Human Genome
KEY CONCEPTS
- The human genome is subdivided into a large nuclear genome with more than 26,000 genes, and a very small circular mitochondrial genome with only 37 genes. The nuclear genome is distributed between 24 linear DNA molecules, one for each of the 24 different types of human chromosome.
- Human genes are usually not discrete entities: their transcripts frequently overlap those from other genes, sometimes on both strands.
- Duplication of single genes, subchromosomal regions, or whole genomes has given rise to families of related genes.
- Genes are traditionally viewed as encoding RNA for the eventual synthesis of proteins, but many thousands of RNA genes make functional noncoding RNAs that can be involved in diverse functions.
- Noncoding RNAs often regulate the expression of specifi c target genes by base pairing with their RNA transcripts.
- Some copies of a functional gene come to acquire mutations that prevent their expression. These pseudogenes originate either by copying genomic DNA or by copying a processed RNA transcript into a cDNA sequence that reintegrates into the genome (retrotransposition).
- Occasionally, gene copies that originate by retrotransposition retain their function because of selection pressure. These are known as retrogenes.
- Transposons are sequences that move from one genomic location to another by a cut-andpaste or copy-and-paste mechanism. Retrotransposons make a cDNA copy of an RNA transcript that then integrates into a new genomic location.
- Very large arrays of high-copy-number tandem repeats, known as satellite DNA, are associated with highly condensed, transcriptionally inactive heterochromatin in human chromosomes.
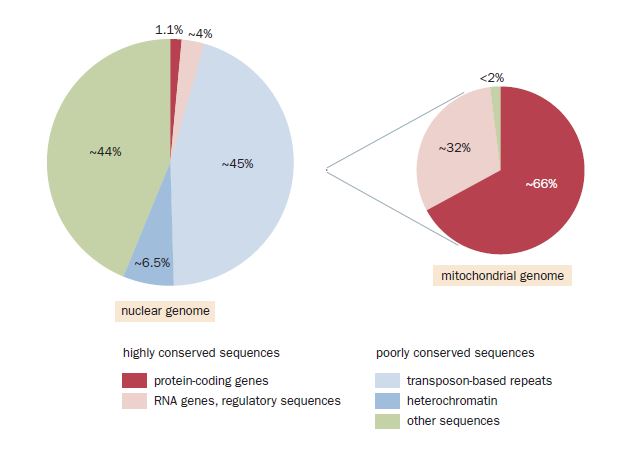
The human genome comprises two parts: a complex nuclear genome with more than 26,000 genes, and a very simple mitochondrial genome with only 37 genes. The nuclear genome provides the great bulk of essential genetic information and is partitioned between either 23 or 24 different types of chromosomal DNA molecule (22 autosomes plus an X chromosome in females, and an additional Y chromosome in males). Mitochondria possess their own genome—a single type of small circular DNA—encoding some of the components needed for mitochondrial protein synthesis on mitochondrial ribosomes. However, most mitochondrial proteins are encoded by nuclear genes and are synthesized on cytoplasmic ribosomes before being imported into the mitochondria. sequence comparisons with other mammalian genomes and vertebrate genomes indicate that about 5% of the human genome has been strongly conserved during evolution and is presumably functionally important. Protein-coding DNA sequences account for just 1.1% of the genome. The other 4% or so of strongly conserved genome sequences consists of non protein-coding DNA sequences, including genes whose final products are functionally important RNA molecules, and a variety of cis-acting sequences that regulate gene expression at DNA or RNA levels. Although sequences that make non-protein-coding RNA have not generally been so well conserved during evolution, some of the regulatory sequences are much more strongly conserved than protein-coding sequences. Protein-coding sequences frequently belong to families of related sequences that may be organized into clusters on one or more chromosomes or be dispersed throughout the genome. Such families have arisen by gene duplication during evolution. The mechanisms giving rise to duplicated genes also give rise to nonfunctional gene-related sequences (pseudogenes). One of the big surprises in the past few years has been the discovery that the human genome is transcribed to give tens of thousands of different non coding RNA transcripts, including whole new classes of tiny regulatory RNAs not previously identified in the draft human genome sequences published in 2001. Although we are close to obtaining a definitive inventory of human protein-coding genes, our knowledge of RNA genes remains undeveloped. It is abundantly clear, however, that RNA is functionally much more versatile than we previously suspected. In addition to a rapidly increasing list of human RNA genes,we have also become aware of huge numbers of pseudogene copies of RNA genes. A very large fraction of the human genome, and other complex genomes, is made up of highly repetitive non coding DNA sequences. A sizeable component is organized in tandem head-to-tail repeats, but the majority consists of interspersed repeats that have been copied from RNA transcripts in the cell by reverse transcriptase. There is a growing realization of the functional importance of such repeats. In this article we primarily consider the architecture of the human genome. We outline the different classes of DNA sequence, describe briefly what their function is, and consider how they are organized in the human genome. In later article we describe other aspects of the human genome: how it compares with
other genomes, and how evolution has shaped it, DNA sequence variation and polymorphism, and aspects of human gene expression.

No comments:
Post a Comment